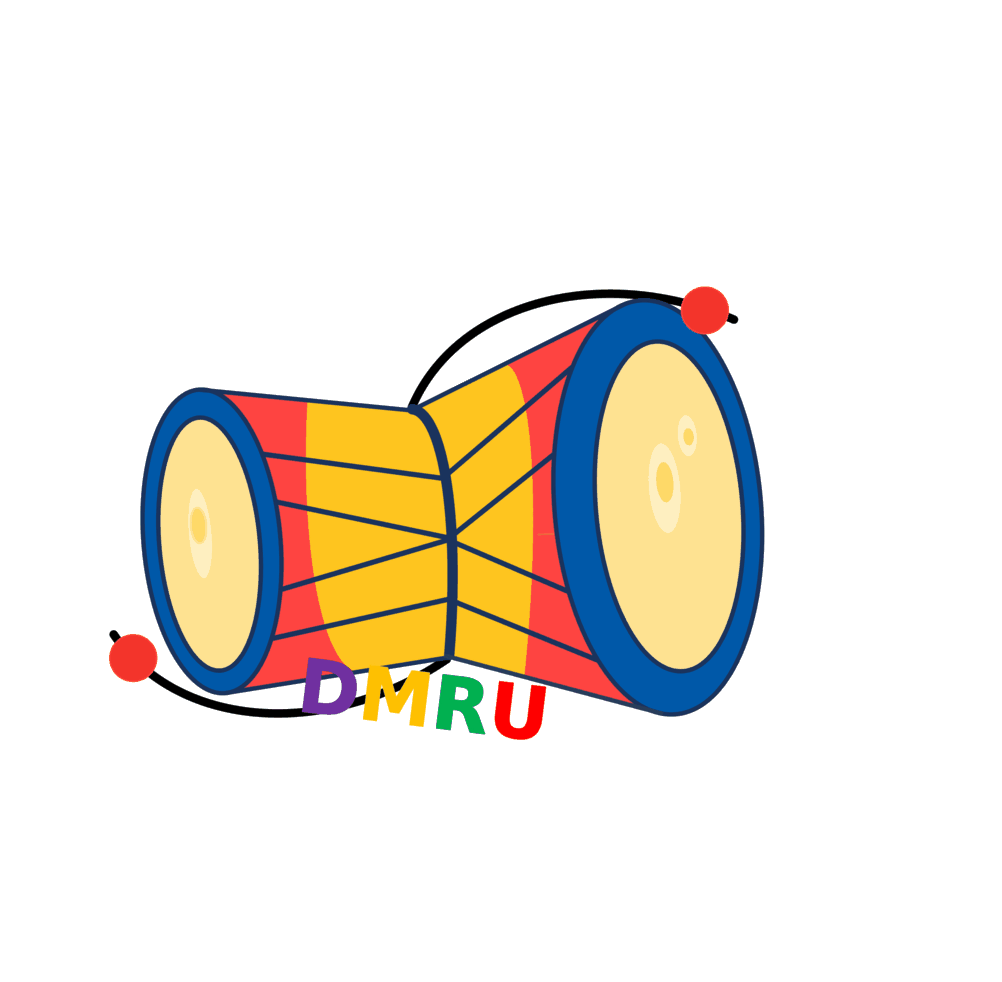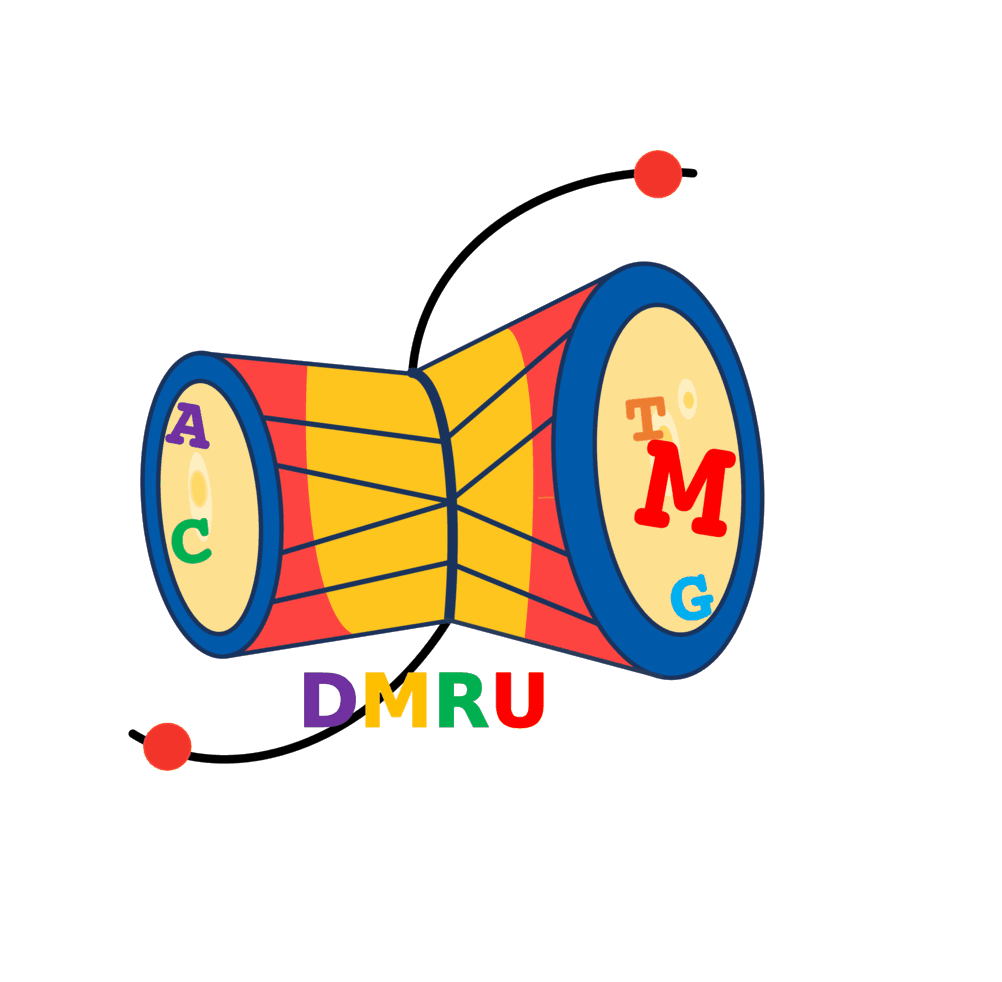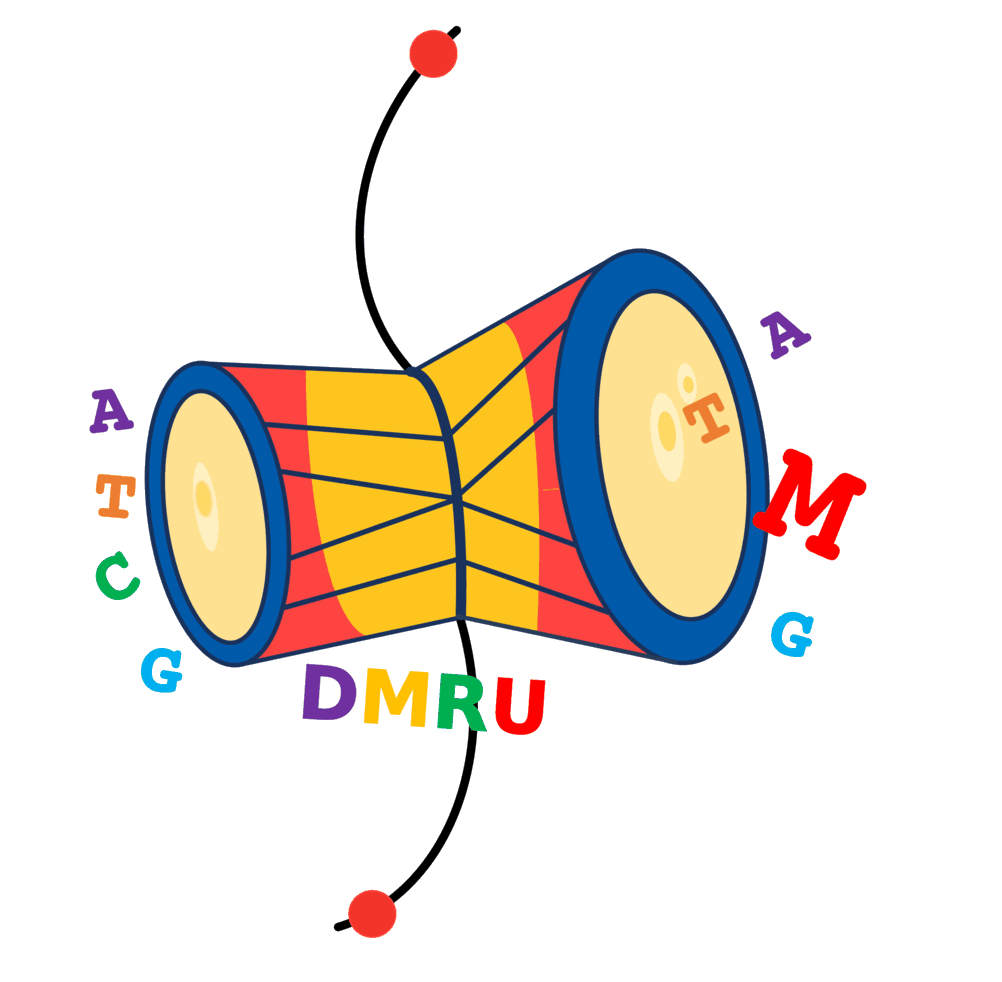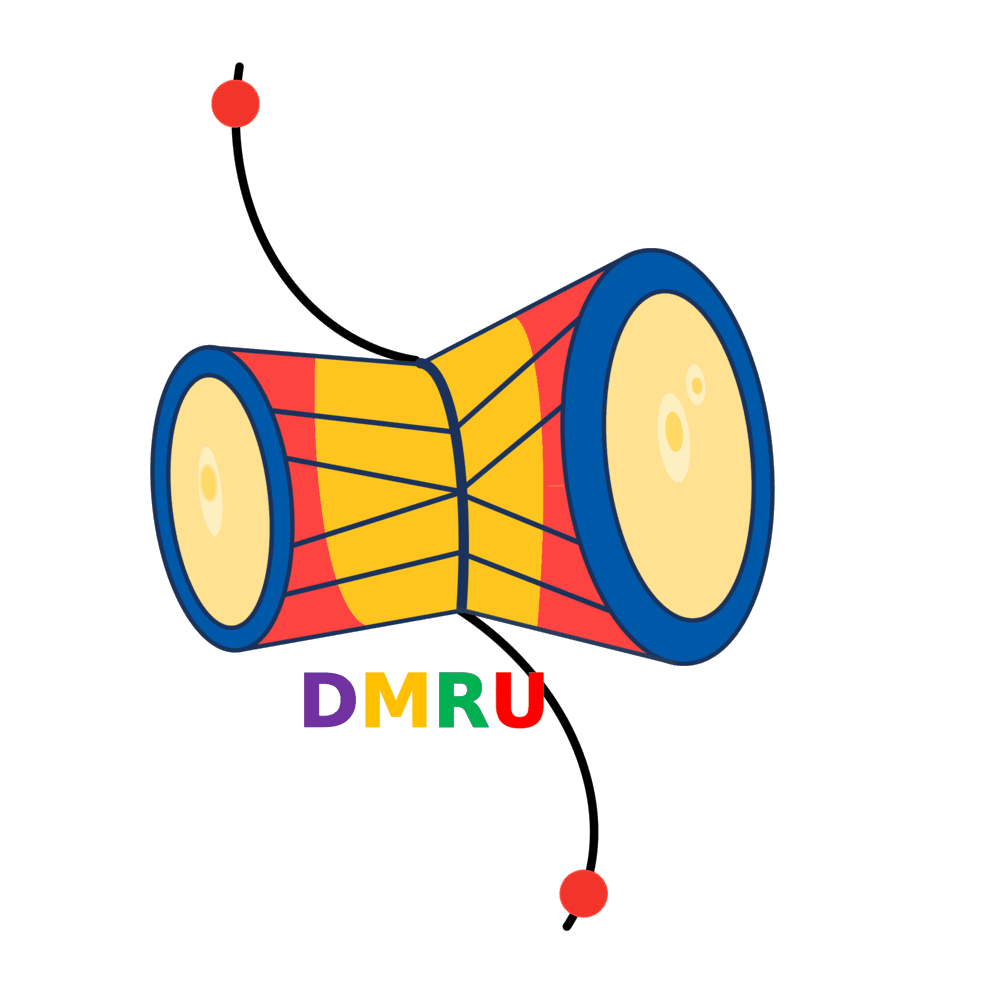
Figure: Implementation of the DMRU Deep Co-learning system using Transformers and DenseNet to annotate DNA methylation. The encoder processes the promoter sequences, without methylation representations, in penta, hexa, and heptamer words representations, while the decoder receives the methylated sequences representations for the corresponding sequence. Eight layers of encoder:decoder pairs were incorporated. In the parallel, a DenseNet consisting of 121 layers accepts input in the form of the associated RNA expression profile. The learned representations from the encoder and DenseNet are merged and passed to the encoder-decoder multi-head attention layer, which also receives input from decoder layers. Subsequently, the resulting output undergoes conditional probability estimation, playing a pivotal role in the decoding process. Following layer normalization, the model proceeds to calculate the conditional probability distribution over the vocabulary for the next token. Finally, the resultant tokens were converted back into words, representing the methylated states for the given sequence.